Unveiling How Vector Search Works
Vector Search is a game-changer for retailers striving to enhance their online user experience, boost conversion rates, and increase their online revenue.
In this article we are going to delve deeper into how this transformative technology actually works.
We’ve recently covered the basics and the main benefits of vector search, an emerging technology that’s redefining how we search and shop online.
Check our mini video series on the topic too! Now let’s see the technical aspects of vector search.
Mathematical representation of information
The key difference between vector and keyword search lies in the way data is represented and compared.
Traditional search methods treat data as a collection of words, focusing on the presence or absence of specific terms. Vector search, on the other hand, uses vector embeddings to represent data points.
Vectors are essentially mathematical representations of objects, whether they be words, products, or images.
Each product in an E-commerce catalog is translated into a vector in a high-dimensional space. These dimensions can represent various product attributes. For example, movies might be represented as vectors where each dimension represents a movie feature (e.g., genre, director, actors, etc.).
By operating in high-dimensional spaces, the search algorithm can capture intricate relationships and similarities between products. For example, products with similar attributes will have vectors that are closer in this multi-dimensional space.
Vectorization methods

To create vector representations, you can use various techniques, such as Word2Vec, Doc2Vec or deep learning models like convolutional neural networks (CNNs) or recurrent neural networks (RNNs). The choice of machine learning method depends on the data and the problem you are trying to solve.
In the E-commerce setup, methods like word embeddings (for textual product descriptions), product embeddings (based on their attributes), session data embeddings (that adds up to a user profile), and hybrid models that combine multiple vectorization methods might be the most beneficial, providing the best search accuracy.
Indexing
Once you have vector representations for all your items, you need to index them for efficient retrieval.
This is often done using data structures like search trees or more advanced techniques like locality-sensitive hashing (LSH) or approximate nearest neighbor (ANN) indexes. These data structures enable fast nearest-neighbor searches.
Search Query Vector
When a user or system submits a query, it is also vectorized in the same manner as the items. The query vector represents the features or characteristics of the query, which then will be used as a base of similarity to find the relevant products in stock.
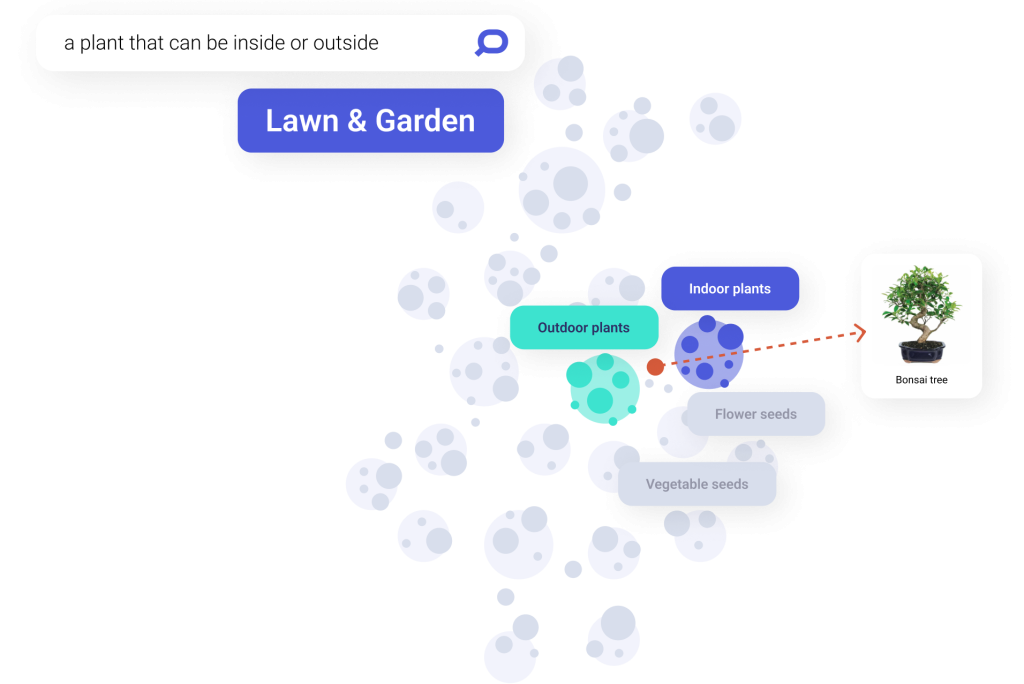
Similarity Metrics
To find similar items in vector databases, you need a way to measure the similarity between the search query vector and the vectors of items in the dataset. Common similarity metrics include cosine similarity, Euclidean distance, L2 distance and Jaccard similarity, among others.
Closeness in space means more vector similarity, whereas more distance means fewer common characteristics. Businesses using a vector search engine could perform nearest-neighbor searches to determine distance metrics to the closest query-related vectors in a space.
Utilizing the joint power of keyword and vector search
When vector search and keyword search results are blended, it’s called a hybrid search solution.
A hybrid search engine that combines keyword-based and vector-based approaches offers a more robust and versatile solution, providing highly relevant search results across a wide range of scenarios.
But how exactly are keyword and vector search results blended?
There are multiple different ways, but here’s how we do it at Prefixbox:
In a vector-based search result, you can still have traditional keyword-based search scores, like
- the matching score, which shows how relevant the result is for a specific search query, and
- the popularity score, which shows how popular a specific search result is.
In addition to these scores, the vector-based search results have similarity scores, which are based on the mathematical representation of the keyword, and its distance from the result in the vector space.
Blending is the method of merging the result lists. This can be achieved by scaling and normalizing these scores by applying weights in order to get the best ranking.
Summary
Vector search is a technique used to find similar items in a large dataset based on their vector representations. Applications span from content recommendation to image retrieval and E-commerce product recommendations.
It’s the critical element that empowers recommendation systems to deliver more insightful suggestions and fine-tunes search engines for superior performance.

